If you glance at an
Ethereum block, among all the important looking stuff is an almost afterthought called the "stateroot" (or "root hash", or "root", if it is even mentioned at all). People who just want to trade a bunch of Ether should just ignore that weirdo tag (and everything else in a blockchain explorer) and head straight to Coinbase.
But, for anyone interested in the technology behind blockchains, this "stateroot" is one of the most important concepts. It's so important, that I am forgoing an evening in hip Brooklyn to stay in and passionately write about it.
The stateroot is one of those topics that you can relearn at progressively deeper levels, so I'll build up the discussion across a few posts, starting here with its description as an interesting low level piece of plumbing, then go deeper in future posts....
If you push aside all the hype, a blockchain is basically a database. It happens to be a globally shared database designed to thrive under hostile and paranoid conditions, run by opportunistic volunteers begrudgingly syncing state... but a database nevertheless.
How one coerces hostile adversaries to maintain the state of a database is an interesting topic, but for now, let me focus a simpler sub-question. How can you even *know* that two databases hold identical data, even in the best of circumstances?
Let's say you and your buddy have two copies of the same evolving database, one in Topeka, the other in Kathmandu. You *think* that they are in sync, but need to *prove* this. This database is big-ish, say, 500GB, and the number of updates is small-ish, say, 100 or so per every 15 seconds (a bit like, say, a blockchain?).
How do you show that the Topeka and Kathmandu data are identical, ideally in realtime?
A really dumb way to try to do this would be to just send a copy of the full database from Topeka to Kathmandu over the internet (and forgo any possibility of watching Netflix for the next 24 hours), then do a giant diff.
Right about now, a scowling developer just threw his coffee mug at the computer screen and angrily yelled "You idiot! This is trivially solved using a hash function".
This is the usual way that we verify that two blobs of data are identical. Some mysterious crypto function (with a strange name like "SHA" or "Keccak") converts each and every byte of data in a giant dataset into one single line of gibberish. If the gibberish in Topeka and Kathmandu match, so do the databases (more accurately, if the hashes match, it would be
statistically impossible for the databases to differ).
While this is much less "really dumb" than just sending the full dataset across the world, it still doesn't work all that well. SHA'ing all that data will take about half an hour, way longer than the 15 second modification time. And the computer is going to be pretty unusable with this nonstop SHAing going on (remember, it still has to act as a functional database during all of this).
Honestly, it would probably take 10 minutes to just output all the data straight to /dev/null, much less run it through a hash algorithm. So this is a deeper problem than "just get a quicker algorithm" can fix. We need to rethink the hashing process itself.
The real problem here is that every single update triggers a full recalculation of the hash. It would be ideal if we could find a hash function that could be updated quickly, then just evolve it alongside the database from some known point in time (perhaps early along when the database was much smaller). Anticipating changes in a hash
almost seems inconsistent with the spirit of hash functions, but as long as those changes themselves are unpredictable, it is not. In fact, as I am about to show, there is a simple way to modify any pre-existing hash function to have this property.
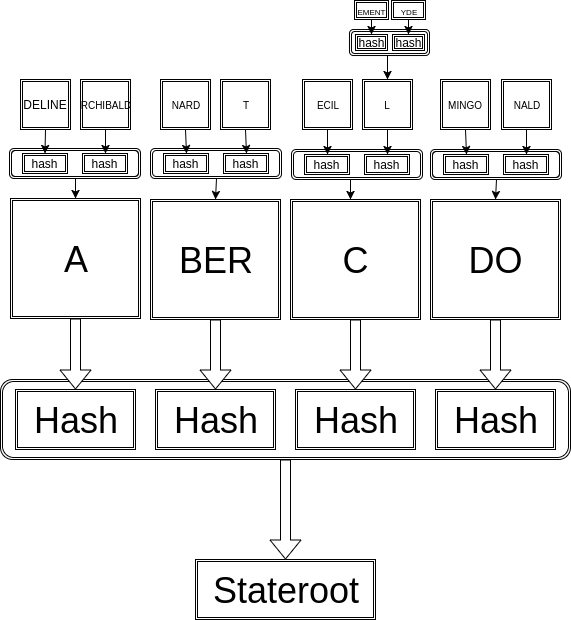
The standard way to deal with just-too-large of a problem is to break it into many smaller pieces. For instance, imagine every bank balance in the entire world in a database:
| Adeline | $10 |
| Archibald | $41 |
| Bernard | $72 |
| Bert | $2 |
| Cecil | $17 |
| Clement | $18 |
| Clyde | $45 |
| Domingo | $57 |
| Donald | $82 |
| .... and so on | |
That will take some serious time to hash, for arguments sake, let's say, half an hour (a tiny understatement).
Instead, let's use the first letter of each name to split this into sub-databases (Adeline and Archibald are in the 'A' sub-database, Bernard and Bert in the 'B', etc). Topeka and Kathmandu now need to verify that 26 hashes are the same... or, better yet, realizing that the list of hashes itself is just data, hash that blob and compare just that one single hash. (Yes, this is the hash of a hash, and yes, that is kind of weird.... but, let's live a little!).
Now, if Clement earns $7, you just rehash the 'C' database and Kathmandu will know in record time that all is good. This is definitely a win, as our resync (of a 500GB database) is about a minute, and we still just pass around a single hash.
While better, one minute per hash isn't good enough. To keep up with all the changes, the CPU would be maxed all the time. We could start fine tuning the number of divisions (smaller chunks=faster hashing/extra overhead on the secondary hash), but there is a better way.
The magic is.... You can split sub-databases themselves. All the good stuff that happened when we split our big database into smaller ones repeats when we split those into smaller ones (and so on). For instance, the 'A' database above can be split into 'AA', 'AB', 'AC', etc. And those can be split further, until each sub-sub-etc-database contains one single item. This is much better than just adding subdivisions to the one one level split, because the size of the data you need to hash for a single update remains small (ie- grows logarithmically with the number of accounts).
This process shatters the database into a beautiful tree. You wander up the tree using paths determined by the letters of the username (A-D-E-L-I-N-E). Each branchpoint is populated with the hashes of hashes of hashes (="hashception"?), etc going down away from the leaves. And at the root lies one single hash, called the "root hash", which itself *is* a hash that can be used to verify all the data in the database.
In the special case where your data just happens to hold the full state of a giant globally shared database in a hostile and paranoid environment (AKA- a "blockchain"), we call that particular "root hash" the "stateroot".
(yeah, I mashed together some of the linear parts of the tree in the diagram above in places where it would have been stupid not to....)
This tree is called "
the Merkle Patricia Trie", in case you are interested, and it has applications that go beyond just hashing stuff. You can read more about this
here and
here.
The stateroot is a hash with some amazing properties:
1. Fully calculating a stateroot is effectively as fast as calculating a SHA, however
2. Updating a stateroot from a change in the database is effectively immediate. This means that
3. You can verify two databases are in sync in realtime.
These next two points kind of blow me away:
4. A stateroot can be used to
verify just a single item in a database, *even if you don't have any other data in that database*. (You will also need to download a small metadata "proof" called the "Merkle branch" that ties this value to the stateroot).
5. Likewise, you can update a stateroot from a single change in the database *even if you don't have any other data in that database*, as long as you have the Merkle branch to that point.
For now, you can almost think of a stateroot as a hash with a sort-of-kind-of concept of locality. As described above, you can both update and verify from just some local data.
It is these two points that made me suspect that the concept of the stateroot goes deeper than just hashing.... I will delve into this more in my next stateroot post.