In source code, a database is usually treated as an an idealized abstract concept.
Real databases have tons of features. In a recent project, we connected to 12 databases with plugable vendors, configurable locations, load balancing, automatic backup, and local caching. Sometimes our "database" wasn't a single thing, but a distributed or logical entity, or maybe a mysterious cloud based web service (yes, the phrase DaaS is actually a thing).
Without abstraction, dealing with all of this would be madness. Imagine having to chase data across the physical machines in a distributed filesystem, in the code at the middle of a soup sharing app. When programming, configurable database features are just nuisance. A developer just wants to plop a tiny data hobgoblin down on the system that feeds and expels information upon request.
And that is basically what engineers created.
In source code, the oddly named object called the "handle" is a small pointer to an idealized, single-minded data hobgoblin. At runtime, we can wire up a handle to point to a real database. A handle is a promise that someday some devops guy is going to set up an actually useful backend, but today we are free to store everything in shoddily configured SQLite.
Handles are black boxes. Internally, they tend to be pointers to opened network connections or unix sockets, or even something as simple as a unique ID that the backend stores in a lookup table, but mostly, developers neither know nor care what is inside.
A blockchain *itself* is a very abstract database. It is a logical collection of mutually hostile peers competing to steer the future of the data they hold. But, it is still a thing that holds data, and the data can be queried. Might we want to bake a "handle" into our blockchain APIs?
So, how *do* you query a blockchain? What if you want to ask the simple question "how much money do I have?".
Even this basic task is slightly complicated. You can find an arbitrary peer in the network to query, but peers often lag in syncing up. Or worse yet, since blockchain updates are always subject to some wheeling and dealing, peers might temporarily disagree with each other on reality itself. At any given moment, the state of the database is in a hodgepodge of competing snapshots. We need a way to label each candidate snapshot, and include this label in any query. This will give us unambiguous results, independent of the opinions of the peer you happen to be connected to.
Or to put it differently, we need a database handle. Just like before, we just want a simple object that points to an idealized information hobgoblin (in this case a database snapshot). Once we have this pointer, we will include it in any query to indicate which database snapshot we would like to query.
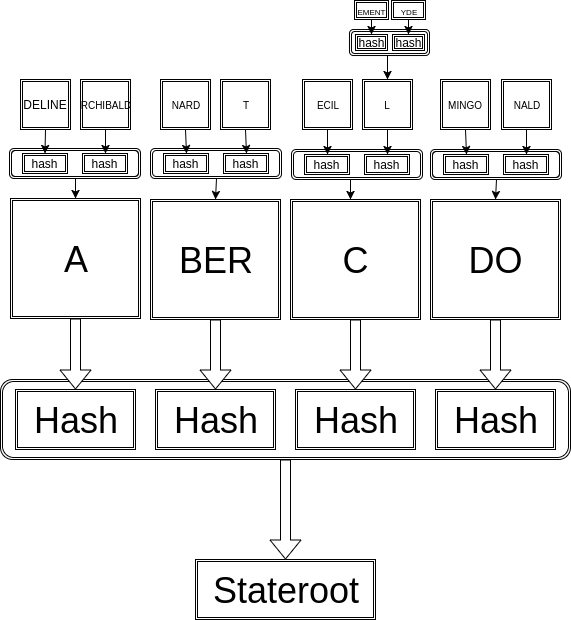
The stateroot of a database is statistically unique, and peers already pass them around as a hashes to verify data integrity. Stateroots therefore are a perfect handle.
Whenever you want to query some data, you select your favorite snapshot, then include its stateroot as a handle in your query. The peer will know which snapshot it refers to, and can perform the query against it.
This works great in resolving accidental ambiguity, but how do you know that the peer you connected to isn't lying to you?
When we connect to a simple local non-blockchain SQL database that the devops guy has set up, we trust the data it returns.
On the other hand, when we connect to an arbitrary peer in a blockchain network, you have no way to know whether it is run by the Bank of Norway, some kid doing a blockchain experiment for his high school class, or Bernard Madoff. Most folks are good at heart, but you should just assume that you've connected to an evil buffoon.
Luckily, a stateroot isn't just a handle.... It is a *cryptographic* handle!
(Of course, deciding whether you should trust a snapshot is the job of mining.... so I won't get into that here).
There is one last oddity that I want to mention. If you update a database, you can also quickly recalculate its stateroot, even if you don't have any other data in the database, as long as you have the Merkle Branch to the location being modified.
You might think this could extend our discussion of blockchain querying to include updating, but this definitely is not the case. Remember, a blockchain database is locked down to changes, which can only occur through the ceremonial process of submitting transactions and mining. There is no technical reason that the API could not include direct updates, but it would be undesirable to allow it.
However, at a lower level, within the software that powers a blockchain node, this is exactly how updates are performed. This process allows us to view the evolution of a database as succession of stateroots over time.
I personally find this idea very cool, and will cover it in part 3.